Reasoning Tasks in Generative Text Models


Currently, more focus is given to reasoning in generative text models. In this blog post, we will research the limits of reasoning in current generative text models and possible solutions.
GPT-3 and Logic Puzzles
GPT-3 fails at some logic puzzles. Let's example a puzzle which does not have an answer and should not be solvable.
You are a detective trying to solve a puzzle. You have three suspects: John, Paul, and George. You know that one of them is the perpetrator, but you don't know which one. You have the following information:
- John is taller than Paul
- George is shorter than Paul
- The perpetrator is left-handed
What is the solution to this puzzle and why?The answer by GPT-3 was the following:
If we assume that the perpetrator is John, then we can see that this does not fit with the information given. Since John is taller than Paul, and George is shorter than Paul, this means that the perpetrator must be George.Now let's look at a puzzle involving the Pigeonhole Principle. That is a puzzle in which you can find the answer by excluding answers. The following puzzle can be solved by the Pigeonhole Principle:
Alice, Bob, and Cecile are wearing a blue, green and a red shirt.
- If Cecile wears a green shirt, then Alice wears a blue shirt.
- Cecile wears a green shirt.
Who is wearing which shirt?Can you find the answer to this puzzle? The correct answer is Cecile=green, Alice=blue, Bob=red. However, GPT-3 comes with this incorrect answer:
GPT-3: Alice is wearing a blue shirt, Bob is wearing a green shirt, and
Cecile is wearing a red shirt.As you can see, GPT-3 is not good at solving all types of reasoning puzzles. How can we improve the reasoning capabilities of GPT-3?
Chain-of-Thought Prompting
Chain-of-Thought prompting [1] is a technique in which you explicitly ask the model to come up with an explanation to the answer. This is done by adding "Let's think step-by-step." to your prompt. Here you can see some examples of Chain-of-Thought prompting:
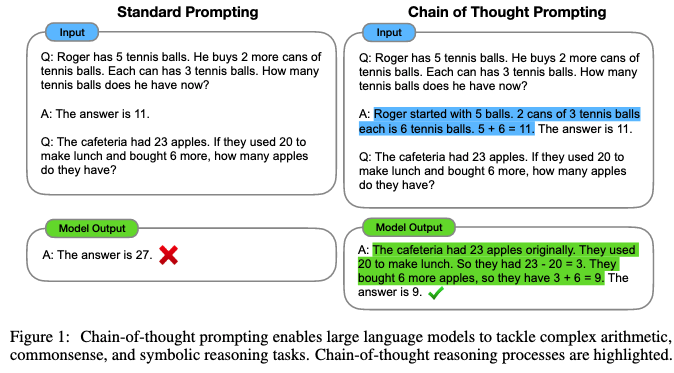
With Chain-of-Thought prompting, we can get better answers, especially for numerical reasoning. But it will still not be good enough for the capabilities of the AI for more complex reasoning challenges.
Challenges of Complex Reasoning on LSAT
Some research has been done on complex reasoning and AI [2]. In the Complex Reasoning [2] paper, we can see several error types when an AI is tested on LSAT (Law School Admission Test):

Simple reasoning tasks which involve only one or two steps are relatively easy for generative models. However, once it gets more complex, the model makes more and more errors.
Conclusion
GPT-3 is not perfect and struggles with reasoning tasks. In this blog post, you have seen several examples of reasoning tasks and how GPT-3 performs on them. As researchers continue to explore advancements in artificial intelligence, addressing these limitations in reasoning will be crucial for the development of more robust and versatile AI systems.
References
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models (arXiv:2201.11903). arXiv. http://arxiv.org/abs/2201.11903
- Wang, Siyuan, Zhongkun Liu, Wanjun Zhong, Ming Zhou, Zhongyu Wei, Zhumin Chen, and Nan Duan. 2021. ‘From LSAT: The Progress and Challenges of Complex Reasoning’.