Automatic Text Summarisation: Overview and Challenges


The amount of information that we consume is growing every day. As a consequence, we need mechanisms to compress this growing amount of information. Text summarisation is a tool for compressing written text and has been used for ages. At this moment, the amount of information is growing exponentially as of which it might be helpful to design models that can automatically summarise texts for us.
Historical Notes
Automatic text summarisation comes in two flavours: extractive summarisation and abstractive summarisation. Extractive summarisation models take exact phrases from the reference documents and use them as a summary. One of the very first research papers on (extractive) text summarisation is the work of Luhn [1]. TextRank [2] (based on the concepts used by the PageRank algorithm) is another widely used extractive summarisation model.
In the era of deep learning, abstractive summarisation became a reality. With abstractive summarisation, a model generates a text instead of using literal phrases of the reference documents. One of the more recent works on abstractive summarisation is PEGASUS [3] (a demo is available at HuggingFace). PEGASUS can summarise the following Wikipedia article:
Python is an interpreted high-level general-purpose programming language.
Its design philosophy emphasizes code readability with its use of significant indentation.
Its language constructs as well as its object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects.
Python is dynamically-typed and garbage-collected.
It supports multiple programming paradigms, including structured (particularly, procedural), object-oriented and functional programming.
It is often described as a "batteries included" language due to its comprehensive standard library.
Guido van Rossum began working on Python in the late 1980s, as a successor to the ABC programming language, and first released it in 1991 as Python 0.9.0.
Python 2.0 was released in 2000 and introduced new features, such as list comprehensions and a garbage collection system using reference counting.
Python 3.0 was released in 2008 and was a major revision of the language that is not completely backward-compatible.
Python 2 was discontinued with version 2.7.18 in 2020.
Python consistently ranks as one of the most popular programming languages.As output, it then generates the following (abstractive) summary of this text:
Python is a programming language developed by Guido van Rossum.What I find interesting, is that this exact phrase cannot be found in the reference document and that one model is capable of compressing textual information automatically. However, there are some challenges with abstractive text summarisation as well which are explored in the next section.
Challenges for Automatic Text Summarisation
In this section, several challenges for automatic text summarisation will be discussed as well as potential research directions.
Controlling the Outputs
What are the challenges that we are facing with these kinds of models? Are these models perfect? No, and that directly brings me to the first point: how can we measure the "quality" of a summary? In the past, several metrics are developed. Such as ROUGE and BLEU (which roughly measure the amount of overlap between the generated summary and the reference text). But what "fluency" (the grammatical and semantical correctness of a text)? And factual correctness? One issue with abstractive models is the generated output might contain words and numbers that are not found in the reference texts. Restricting the vocabulary might be one possible solution for constraining the output [5] which is explained below. Hopefully, more metrics and methods for controlling the outputs will become available.
Multi-document Summarisation
Another challenge is multi-document summarisation, in which multiple documents are summarised into a single summary. This task can be complicated further by using documents of different languages as input. The inputs of this task can become large. Most of the abstractive models are based on Transformers [4] which are known to have a quadratic memory requirement with respect to the number of input tokens. In practice, often 512 subword tokens can be used with Transformer-based models which is a troublesome limitation for the multi-document summarisation task. Luckily, some models are capable of transforming the quadratic memory requirement to a linear memory requirement, such as the Longformer [6] which is explained below. A larger number of datasets on (multilingual) multi-document summarisation together with solutions on decreasing the memory requirement of Transformers might be helpful for multi-document summarisation.
Other Research Directions
Another interesting research direction might be controlling the inputs. What if we can concentrate on only certain aspects of the inputs? Or what if we can combine textual data with image data? Another idea might be to combine text summarisation with other NLP subtasks in order to gain more control over the process.
Possible Solutions
Nucleus Sampling
Constraining the vocabulary as Nucleus Sampling does can help in controlling the output. The authors of [5] mention that generated text often is bland, incoherent or stuck in a repetitive loop. The following image shows these undesirable properties:

To cope with these issues, the authors propose to use Nucleus Sampling: a dynamically sized subset of the vocabulary while predicting the next word, depending on the likelihood of the next word. The authors call this top-p sampling. It is closely related to top-k sampling, in which the top-k vocabulary is used.
An interesting assumption as explained in the paper is that human-written text does not equal the most probable text. They support this assumption by the fact that people optimize against stating the obvious [7] - which is exactly the opposite of optimizing for the most likely text.
The following image illustrates how Nucleus Sampling avoids repetitive loops and incoherent texts in a single example in which the algorithms generate text starting from a given sentence:

Thus, techniques like top-k sampling and Nucleus Sampling (top-p sampling) help in generating more coherent and less repetitive texts which are two undesirable properties in text generation and thus also in automatic text summarisation.
Longformer
One issue for multi-document summarisation is the quadratic memory requirement of Transformer-based models. One solution is the Longformer [6]. As the authors mention, Transformer-based models use attention on all input tokens:
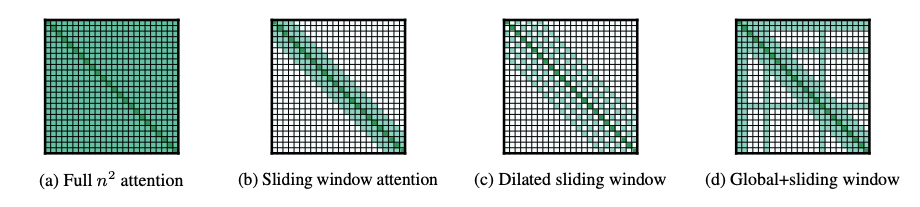
The idea of the Longformer is to use different attention strategies in order to cope with longer inputs. By incorporating special tokens through the text, one can enable the computation of full attention on these special tokens. Therefore, the memory requirement gets reduced to the number of these special tokens times the number of input tokens. To compare: Transformers work on 512 subword tokens, but the Longformer is evaluated on a dataset where some documents contained 14.5K tokens! Besides the Longformer, there are other solutions as well focussing on reducing the quadratic memory requirement, such as Big Bird [8]. Once we can overcome the quadratic memory cost without sacrificing the quality, multi-document summarisation and other tasks related to longer and/or multiple documents can be solved.
Conclusion
The amount of (textual) information is growing exponentially as well as the need for automatic text summarisation tools. Automatic text summarisation is an exciting subfield of natural language processing. Both extractive and abstractive text summarisation methods might bring us solutions for keeping up with the growing amount of information. One challenge for automatic text summarisation is measuring the quality of generated texts and another challenge is the input length constraint in Transformer-based models.
References
- Luhn, H. P. (1958). The automatic creation of literature abstracts. IBM Journal of research and development, 2(2), 159-165.
- Mihalcea, R., & Tarau, P. (2004, July). Textrank: Bringing order into text. In Proceedings of the 2004 conference on empirical methods in natural language processing (pp. 404-411).
- Zhang, J., Zhao, Y., Saleh, M., & Liu, P. (2020, November). Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. In International Conference on Machine Learning (pp. 11328-11339). PMLR.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
- Holtzman, A., Buys, J., Du, L., Forbes, M., & Choi, Y. (2019). The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751.
- Beltagy, I., Peters, M. E., & Cohan, A. (2020). Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150.
- H Paul Grice. Logic and conversation. In P Cole and J L Morgan (eds.), Speech Acts, volume 3 of Syntax and Semantics, pp. 41–58. Academic Press, 1975.
- Zaheer, M., Guruganesh, G., Dubey, K. A., Ainslie, J., Alberti, C., Ontanon, S., ... & Ahmed, A. (2020, July). Big Bird: Transformers for Longer Sequences. In NeurIPS.